
在工程圈有句老话——“cache rules everything around me”。
在 Agent 时代,这句话变成了一个具体到能写进 SLA 的指标:缓存命中率。
Manus 联合创始人 Yichao Ji 说过一句话:
如果让我只挑一个指标,那么 KV-cache 命中率是生产级 AI Agent 最重要的单一指标。
Claude Code 团队更激进——他们把整个 harness 都建在 prompt cache 之上,把缓存命中率列为 SEV(Severity)级监控告警,命中率掉几个百分点,会被当成线上事故。
这听起来像是性能优化范畴的事,其实不是。它决定了三件事:
- 成本:缓存读取只要 base input 价格的 10%,而 Agent 场景输入/输出 token 比能高到 100:1
- 延迟:Prefill 是计算密集阶段,缓存命中等于跳过这一步
- 架构:你 prompt 怎么组织、工具怎么定义、模型何时切换——全部要围绕”前缀稳定”这个约束来设计
这篇文章会把 Prompt Caching 从底层原理讲到工程实践:
- 第一层,缓存到底缓存了什么(KV Cache 与前缀匹配,够用即止)
- 第二层,Anthropic 是怎么把这件事翻译成 API 调用的(block、cache_control、20 块回溯窗口)
- 第三层,定价与失效规则
- 第四层,有哪些实战经验
一、为什么”前缀”可以缓存:一点点底层原理#
要理解 Prompt Caching,只需要记住一件事:
Transformer 推理是自回归的。每次生成下一个 token,都要重新读一遍前面所有 token 的中间状态。
这就给了缓存机会。
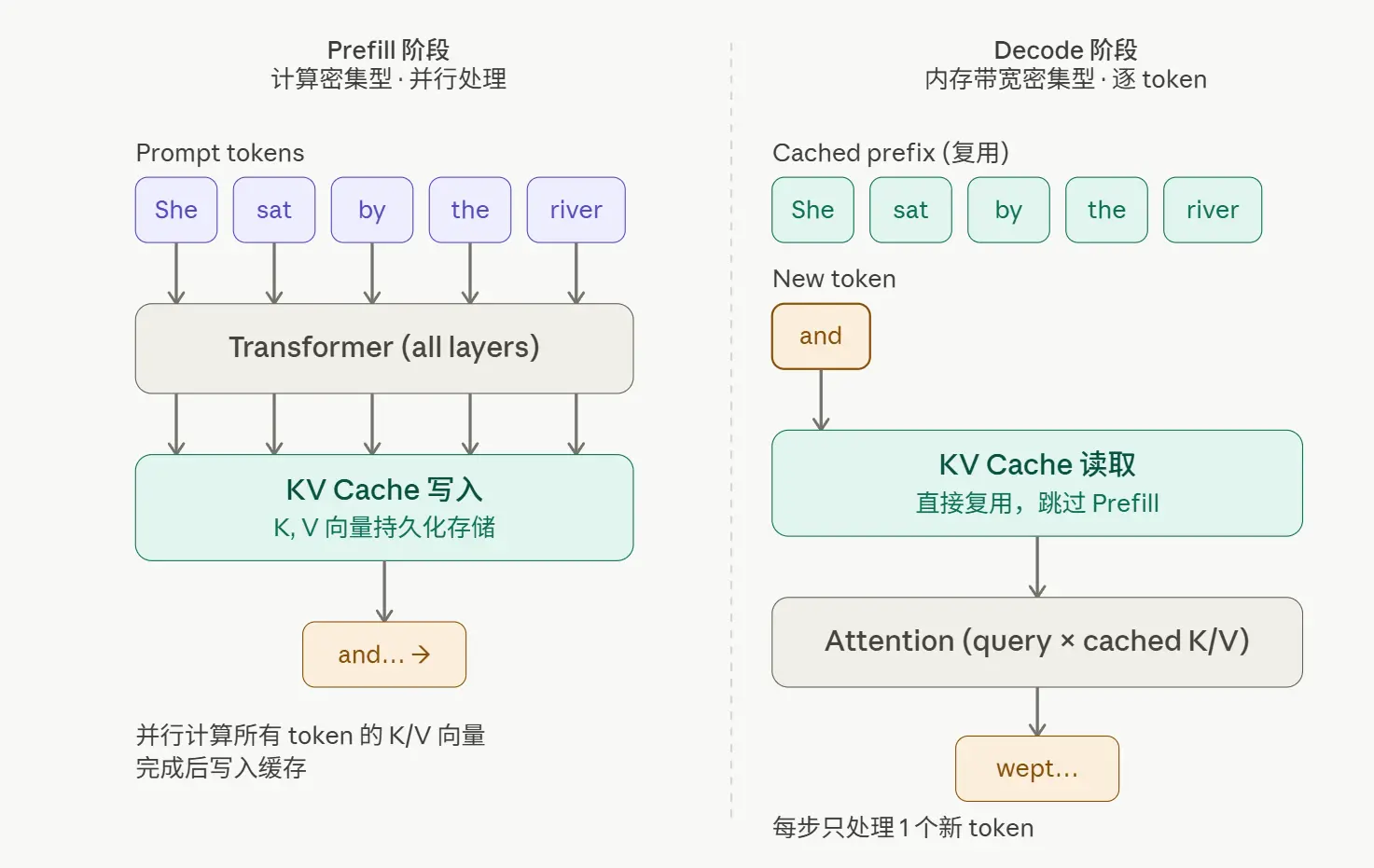
Prefill vs Decode#
LLM 推理通常分两个阶段:
- Prefill 阶段:把 prompt 整体读进来,算出每一层每个 token 的 K(Key)和 V(Value)向量。这一步是计算密集型——堆 GPU 算力解决。
- Decode 阶段:一个 token 一个 token 往外吐。每生成一个新 token,都要拿它的 query 去和前面所有 token 的 K/V 做注意力计算。这一步是内存带宽密集型——拼 HBM 带宽。
如果不缓存,Decode 阶段每生成一个 token 都要把前面所有 token 的 K/V 重算一遍,采样复杂度是 O(n²)。
加上 KV Cache(把 prefill 算出来的 K/V 存下来),复杂度降到 O(n)。
Kipply 在《Transformer Inference Arithmetic》里给过一个具象的数字:KV Cache 计算量约等于完整 forward pass 的 1/6。这意味着每多缓存一个 token,等于省下未来生成时一次完整前向计算的可观比例。
从”单请求 KV Cache”到”跨请求 Prefix Cache”#
上面讲的 KV Cache 是单次推理内的优化——所有 LLM 推理框架默认都做。
而 Prompt Caching 是跨请求复用:第一次请求算完的 KV Cache 不丢弃,留在 GPU 内存(或更慢的存储层)里;第二次请求来了,如果开头一段和上次完全一样,直接复用,跳过 prefill 整个阶段。
SGLang 的 RadixAttention 就是把这些缓存按 Radix Tree 组织,自动做前缀匹配,实测吞吐能比 vLLM 高 5×。Anthropic 内部的实现细节没公开,但对外暴露的 API 抽象就是同一回事:前缀匹配 + 哈希校验。
这里有一个关键约束,后面所有工程经验都从它派生:
因为 Transformer 是自回归的,token N 的 KV 依赖 token 0 到 N-1 的所有内容。 前缀里任何一个 token 不一样,后面全部的缓存都失效。
从那个不一样的 token 开始,后面全部作废。
二、Anthropic 是怎么把这件事工程化的#
理论很简单:前缀匹配。但真要做成 API,需要回答一堆具体问题:
- 用户怎么标记”我想缓存到这里”?
- 缓存的粒度是什么?
- 命中怎么判定?
- 缓存能留多久?
Anthropic 给出的答案围绕三个概念:block、cache_control 断点、回溯窗口。
2.1 什么是 Block#
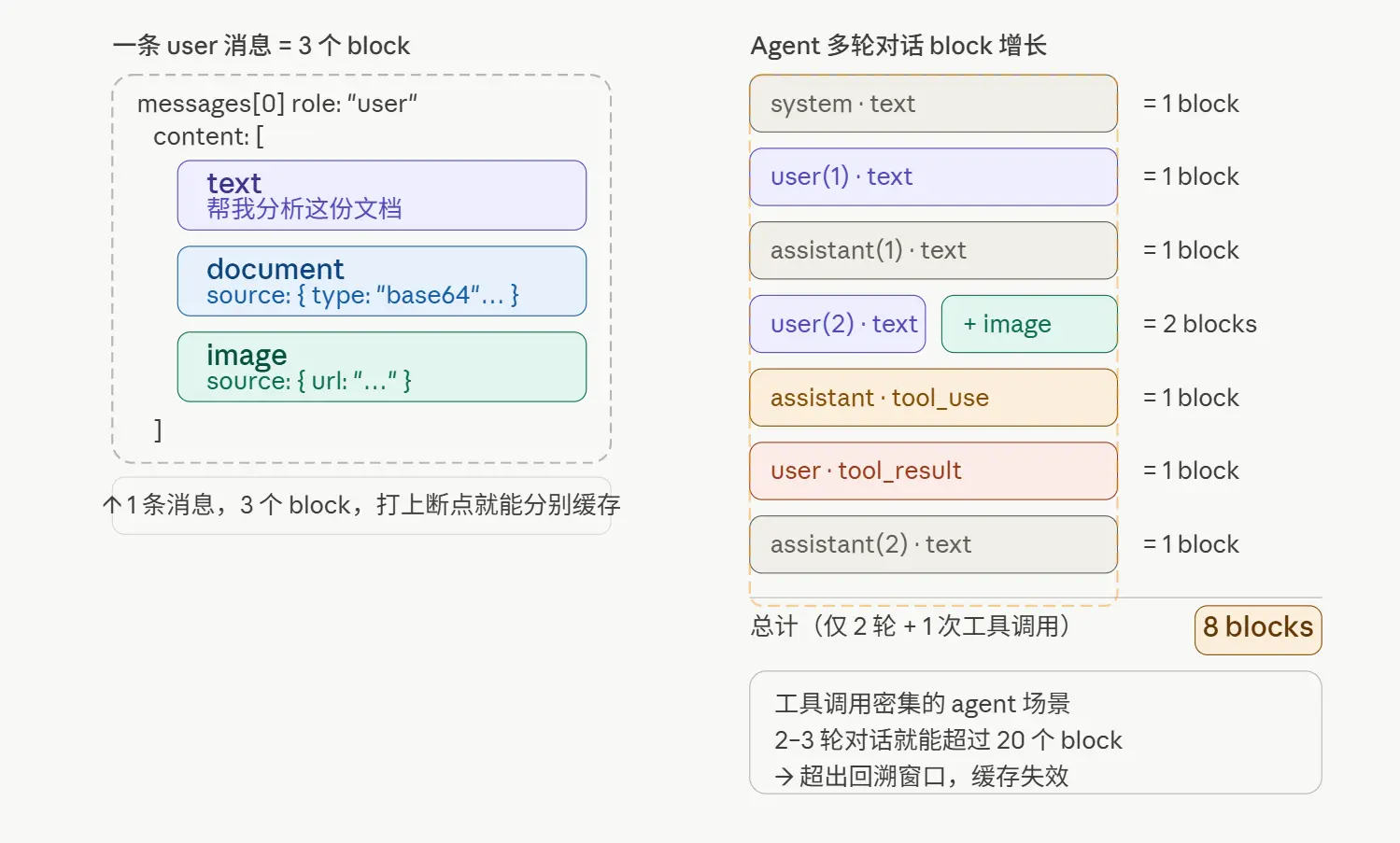
Claude API 一条消息的 content 字段是一个数组,数组里每一个对象就是一个 block:
{
"messages": [
{
"role": "user",
"content": [
{ "type": "text", "text": "帮我分析这份文档" },
{ "type": "document", "source": {...} },
{ "type": "image", "source": {...} }
]
}
]
}上面这条 user 消息有 3 个 block。Block 的类型可以是 text、image、document、tool_use、tool_result、thinking 等等。
为什么要在意 block?因为 cache_control 断点是打在 block 上的,而且回溯窗口是按 block 数算的(后面会讲)。
一个典型的 agent 多轮对话,block 数量增长非常快:
系统提示 → 1 个 text block
用户消息 1 → 1 个 text block
助手回复 1 → 1 个 text block
用户消息 2(带图)→ 2 个 block(text + image)
工具调用 → 1 个 tool_use block
工具返回 → 1 个 tool_result block
助手回复 2 → 1 个 text block
...工具调用密集的 agent 场景,两三轮对话就能产生十几个 block。
2.2 cache_control 断点:一个标记,两个含义#
cache_control 是 Anthropic 暴露给开发者的核心控制点,长这样:
{
"type": "text",
"text": "You are a helpful assistant.",
"cache_control": {"type": "ephemeral"}
}把它打在哪个 block 上,这个 block 就是一个缓存断点。断点同时承担两个职责:
1. 写入(Write):这次请求结束时,系统会把”从请求开头到这个断点为止”的所有内容算出一个累积哈希,存进缓存。哈希基于内容,任何一个字符变化,哈希就完全不同——这就是前面那条铁律的具体表现。
2. 读取(Read):下次新请求来,系统在断点位置算出当前的前缀哈希,去缓存里查匹配。命中,就跳过 prefill 直接复用;不命中,再往后看(下面讲回溯窗口)。
2.3 自动缓存 vs 显式断点#
Anthropic 提供两种用法:
自动缓存 —— 在请求顶层加一个 cache_control 字段,系统把断点自动放在请求里最后一个可缓存的 block 上,随对话增长自动后移。
client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
cache_control={"type": "ephemeral"},
system="...",
messages=[...]
)适合多轮对话不断追加的常规场景,断点跟着最新一条消息往后走。
显式断点 —— 在你想缓存的 block 上手动打 cache_control。
{
"system": [
{
"type": "text",
"text": "You are a helpful assistant.",
"cache_control": {"type": "ephemeral"}
}
],
"messages": [...]
}适合有”分层”诉求的场景:比如 system prompt 一周才变一次,而上下文每天变。你想让 system 那段一直命中,就显式打在 system 末尾。
看起来自动缓存就够用了,为什么还需要显式断点? 这就需要讲到A设的”回溯窗口”机制了。
2.4 20 个 Block 的回溯窗口#
理想情况下,如果两次请求前缀完全一样,断点位置也完全一样,缓存能命中,皆大欢喜。但现实是,对话在增长,断点位置在变。
Anthropic 的处理是:每个断点向后回溯最多 20 个 block,挨个去缓存里找匹配。
举个例子:你在请求 1 里把断点打在第 5 个 block 上,缓存写入了”前 5 个 block”的哈希。请求 2 里你想缓存到第 8 个 block,但前 5 个 block 没变。系统会:
- 先算”前 8 个 block”的哈希,查缓存——没命中
- 往前回溯,算”前 7 个”——没命中
- …一直回溯到”前 5 个”——命中!跳过这 5 个 block 的 prefill
但回溯窗口是 20。如果两次请求之间新增的 block 超过 20,旧的缓存条目就掉出窗口,永远找不回了。
这就解释了为什么自动缓存不够用——它只在”最后一个可缓存 block”上放断点,工具调用密集的 agent 场景几轮过后,前面那条 system 末尾的旧缓存条目早就被甩出回溯窗口了。
解决办法:手动加多个断点(API 最多支持 4 个),让旧缓存条目始终在某个断点的回溯窗口内。

三、定价与失效规则#
3.1 定价#
缓存写入有两个有效期档位可选,通过 cache_control 的 ttl 字段切换:
- 5 分钟(默认) ——
{"type": "ephemeral"},写入时收 base 价的 1.25× - 1 小时 ——
{"type": "ephemeral", "ttl": "1h"},写入时收 base 价的 2×
两档的读取价格相同(都是 base 价的 0.1×),区别只在写入溢价和缓存存活时长。任意一次命中都会把这条缓存的 TTL 重置回原值,所以高频会话基本不会过期。
| 模型 | Base Input | 5m Cache Write | 1h Cache Write | Cache Hits | Output |
|---|---|---|---|---|---|
| Claude Opus 4.7 | $5/MTok | $6.25/MTok | $10/MTok | $0.50/MTok | $25/MTok |
| Claude Sonnet 4.6 | $3/MTok | $3.75/MTok | $6/MTok | $0.30/MTok | $15/MTok |
| Claude Haiku 4.5 | $1/MTok | $1.25/MTok | $2/MTok | $0.10/MTok | $5/MTok |
记住三个比例:
- 5min 缓存写入:base 价的 1.25×
- 1h 缓存写入:base 价的 2×
- 缓存读取:base 价的 0.1×
只要某段 prompt 被命中超过 2 次,5min 缓存就开始赚钱了
3.2 最少 token 限制#
不到这个量的 prompt 不会被缓存(静默失败——不会报错,你可能完全不知道):
| 模型 | 最低要求 |
|---|---|
| Opus 4.7 / 4.6 / 4.5, Haiku 4.5 | 4096 tokens |
| Sonnet 4.6 | 2048 tokens |
| Sonnet 4.5, Opus 4.1 / 4.0 | 1024 tokens |
| Haiku 3.5 | 2048 tokens |
3.3 缓存失效触发器#
哪些操作会让 tools / system / messages 三层缓存失效:
| 操作 | Tools | System | Messages |
|---|---|---|---|
| 修改工具定义 | ✘ | ✘ | ✘ |
| 开关 Web search / Citations | ✓ | ✘ | ✘ |
| 修改 Tool choice | ✓ | ✓ | ✘ |
| 添加/删除图片 | ✓ | ✓ | ✘ |
| 修改 Thinking 参数 | ✓ | ✓ | ✘ |
✘ 表示整个会话那一层的缓存全部失效。这就是为什么”中途改工具”是 prompt cache 最大的杀手——它会把 tools / system / messages 三层全清空。
3.4 监控:三个字段#
API 响应的 usage 里有三个字段:
{
"usage": {
"cache_creation_input_tokens": 100, // 这次写入缓存的 token 数
"cache_read_input_tokens": 100000, // 这次从缓存读取的 token 数
"input_tokens": 50 // 未缓存的 token 数(断点之后的新内容)
}
}总输入 = 三者之和。命中率 = cache_read / 总输入。
如果你的 agent 这个数字常时低于 80%,说明 prompt 结构有问题——多半是某个静态前缀里混进了变化的内容,或者中途改过工具/模型。
四、Claude Code 与 Manus 的血泪经验#
理解了机制,工程实践其实只有一条主线:
设计你的整个系统,让前缀尽可能稳定。
下面这些”经验”全是这一条的具体应用。
经验 1:静态在前,动态在后#
Claude Code 的 prompt 是这样分层的:
- 静态 system prompt + Tools(全局缓存,跨所有项目)
- CLAUDE.md(项目级缓存,跨同一项目所有会话)
- Session context(会话级缓存)
- Conversation messages(每轮新增)
变化频率从低到高,从前到后。这样能让最大一段前缀被最多请求共享。
经典反模式:
- 在静态 system prompt 里加精确到秒的时间戳——每次请求哈希都不同,从不命中
- 工具定义顺序非确定(比如某些语言 JSON 序列化键序不稳定)——一样从不命中
- 中途修改工具参数(比如往 Agent 工具的可调用 agent 列表里加一个新 agent)——之后所有请求重建缓存
Manus 团队提到一个细节:Swift 和 Go 的 JSON 序列化默认不保证键顺序,这会悄无声息地破坏缓存,debug 起来非常痛苦。
经验 2:用 Messages 而不是改 System Prompt#
需要给模型传递新信息(比如”现在时间变了”、“用户改了文件”)时,不要去修改 system prompt——那会让 system 这一层缓存全部失效。
Claude Code 的做法:在下一轮 user message 或 tool result 里加一个 <system-reminder> 标签:
<system-reminder>
File foo.py was modified by the user. Re-read it before editing.
</system-reminder>这样新信息以”messages 增长”的方式追加,不破坏 system / tools 这两层的缓存。
经验 3:永远别中途增删工具#
工具定义在 prompt 最前面(在 system 之前),任何工具的增删都会让整个会话所有缓存失效。
这条规则下,有两个非常聪明的设计模式:
设计 1:Plan Mode —— 用工具控制状态,而不是切工具集#
Claude Code 的 Plan Mode 进入时,直觉做法是”只保留只读工具,删掉编辑工具”——但这会让缓存爆炸。
实际做法:工具集永远不变,只是新增了 EnterPlanMode 和 ExitPlanMode 两个工具。用户进入 Plan Mode 时,模型收到一条 system 消息说明”现在在 Plan Mode,别编辑文件,完成后调用 ExitPlanMode”。工具定义本身一字未动。
附带好处:模型自己也能在遇到难题时主动调用 EnterPlanMode 进入计划模式。
设计 2:Tool Search 的 defer_loading#
MCP 普及后,用户可能挂载几十上百个工具。每次请求都把所有 schema 塞进 prompt,既贵又会撑爆 context。但中途删工具会破坏缓存。
Claude Code 的解法叫 defer_loading:先发轻量级 stub(只有工具名),模型通过 tool search 发现有需要时再请求完整 schema。Stub 永远在,顺序永远一样,缓存前缀稳定;只有真正用到的工具才付出 schema 的 token 成本。
Manus 提了同一思路的另一种实现:Mask 而不是 Remove——保持工具定义不变,在 decode 阶段通过 mask token logits 来限制可调用范围。本质上都是”不要动前缀”。
经验 4:永远别中途换模型#
Prompt cache 是模型 specific 的——Opus 的缓存 Haiku 用不了,反之亦然。
一个反直觉的算账:你和 Opus 聊到 100k tokens,想问个简单问题、想省钱切到 Haiku。结果是比让 Opus 直接答更贵——因为 Haiku 要从零重建整个 100k 的缓存。
正确做法:用 subagent。让父会话(Opus)派出一个 subagent(Haiku),把任务上下文打包成”hand-off message”传过去。父会话的缓存不动,subagent 自己短促轻量地完成任务。
经验 5:Cache-safe Forking —— Compaction 不破缓存#
Compaction(上下文压缩)是 agent 跑长了之后必然要做的事:context window 满了,把历史压缩成摘要,带着摘要继续。
反模式做法:开一个独立 API 调用,用一个新的 system prompt(比如”summarize this”)、不带工具,把历史发过去让模型总结。结果是——前缀和主会话从第一个 token 就分叉了,一点缓存都用不上,你要为整个历史付完整的未缓存 input 价。会话越长,越需要 compaction,这一笔越贵。
正确做法(Claude Code 的 cache-safe forking):
- 用完全相同的 system prompt、user context、system context、tool definitions
- 在父会话原有 messages 后追加一条新的 user message,内容是压缩指令
- 从 API 视角看,这次请求和父会话上次请求几乎一样——前缀全部命中,只有新追加的那条压缩指令是新增 token

Anthropic 已经把这个模式直接做进了 API,叫 Compaction API——你不用自己造轮子。
这个 fork 模式的适用范围远不止 compaction:任何需要”派出去做一段独立计算”的场景(总结、技能调用、并行探索),都应该用相同的 cache-safe 参数,以复用父会话前缀。
经验 6:保留错误,不要清理#
Agent 会犯错——这是事实,不是 bug。常见冲动是”清理 trace、重试、reset”——但这会丢失证据。
Manus 的观察是:保留错误能让模型隐式更新自己的”内部信念”,降低重复同样错误的概率。错误恢复是真正 agentic 行为的标志。
从缓存角度看,清理历史还会破坏前缀稳定性——一举两失。
经验 7:Pre-warming 缓存#
应用启动时,可以用 max_tokens: 0 提前把缓存写入,消除首次用户交互的冷启动延迟:
client.messages.create(
model="claude-opus-4-7",
max_tokens=0, # 关键:不生成输出
system=[
{
"type": "text",
"text": "You are an expert...",
"cache_control": {"type": "ephemeral"}
}
],
messages=[{"role": "user", "content": "warmup"}]
)注意:必须用显式断点,自动缓存会把断点放在最末尾的 placeholder 上,预热的就不是你想要的那段。
五、操作手册:落地清单#
5.1 怎么判断有问题#
读 usage 三个字段:
cache_read_input_tokens / 总输入< 80%,说明命中率不健康cache_creation_input_tokens每次都很大,说明前缀被破坏了——查变化频率- 完全没有
cache_read_input_tokens,检查是不是没到最低 token 数(静默失败的常见原因)
5.2 常见踩坑速查#
| 现象 | 大概率原因 |
|---|---|
| 命中率从来不高 | 静态 prompt 里有时间戳/UUID/随机内容 |
| 命中率突然崩盘 | 改了工具定义,或工具顺序变了 |
| Compaction 后命中率清零 | 用了独立 system prompt 做总结(没用 cache-safe fork) |
| 偶尔突然全部 miss | JSON 序列化键序不稳定(Swift/Go 默认行为) |
| 短 prompt 完全没缓存 | 没到最低 token 数(Opus 4.7 是 4096) |
| 并发请求第一个慢 | 缓存 entry 在第一个响应开始后才可用,并发要等首响应 |
六、写在最后#
Prompt Caching 表面是个性能优化,本质是架构约束。
它强制你回答几个问题:
- 你的 prompt 哪些部分应该是稳定的?哪些是会变的?
- 你的工具定义是否有”全局集 + 状态机”的可能,而不是”按需增删”?
- 你的 compaction、subagent、并行探索,有没有共享父前缀?
- 你的 system prompt 里,有没有偷偷塞了时间戳之类破坏缓存的”小聪明”?
如果你的 agent 缓存命中率上不去,问题不在 Anthropic,在你的 prompt 设计。
Claude Code 团队建议:像监控 uptime 一样监控缓存命中率。几个百分点的下滑,在 100:1 输入输出比的 agent 场景里,会被放大成显著的成本和延迟差异。
参考链接#
- Anthropic 官方 Prompt Caching 文档
- Lessons from building Claude Code: Prompt caching is everything — Thariq Shihipar (Claude Code Team)
- Context Engineering for AI Agents — Yichao Ji (Manus)
- Lance Martin on Prompt Caching — Anthropic
- SGLang: Fast and Expressive LLM Inference with RadixAttention
- Transformer Inference Arithmetic — Kipply
- Anthropic Compaction API