
xAI 和 Anthropic 在 2026 年 5 月 6 日宣布合作:Anthropic 将通过 SpaceX 使用 Colossus 1 数据中心的全部算力,用来提高 Claude Pro 和 Claude Max 的服务容量。
Colossus 1 拥有 22 万张以上 NVIDIA GPU,功率容量超过 300MW,是公开信息里最夸张的 AI 超算集群之一。
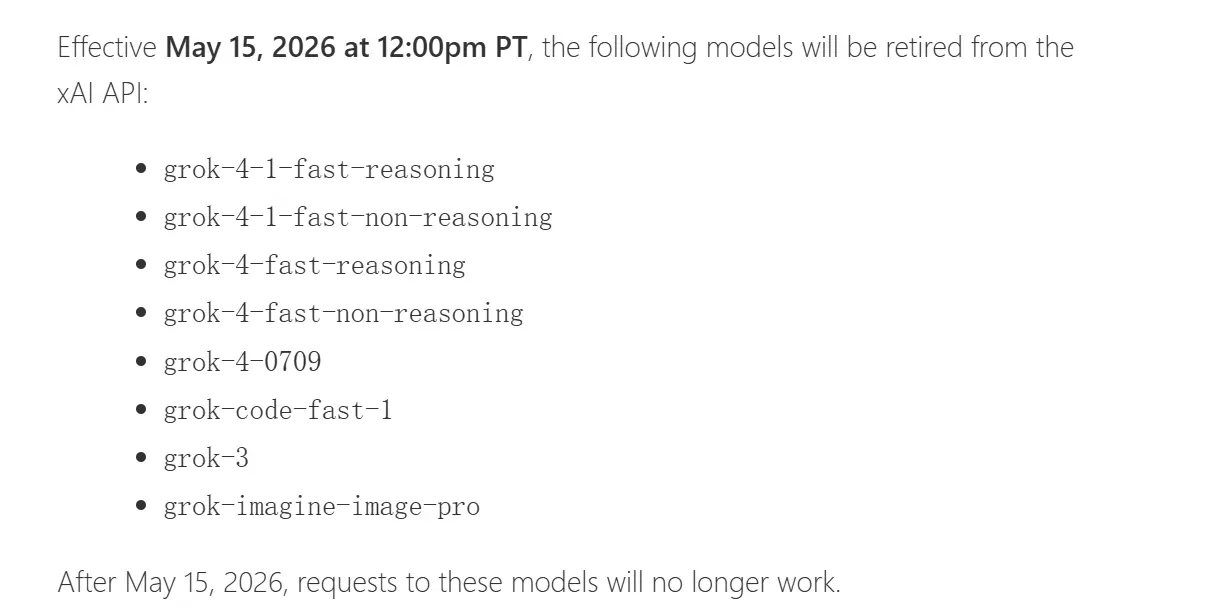
而就在Anthropic宣布与xAI合作的前一晚,xAI发出了一则通知:
Grok 4.1 Fast及多款模型将在两周后下线。
业界纷纷猜测:
xAI要放弃自己的模型了吗?
很多人第一反应:xAI连自己模型的服务都支撑不了,要整个租出去?
Musk 的解释#
Musk 在 X 上的解释大意是:他和 Anthropic 高管见过面,认可对方在 AI 安全上的态度,因此同意把 Colossus 1 租给 Anthropic。
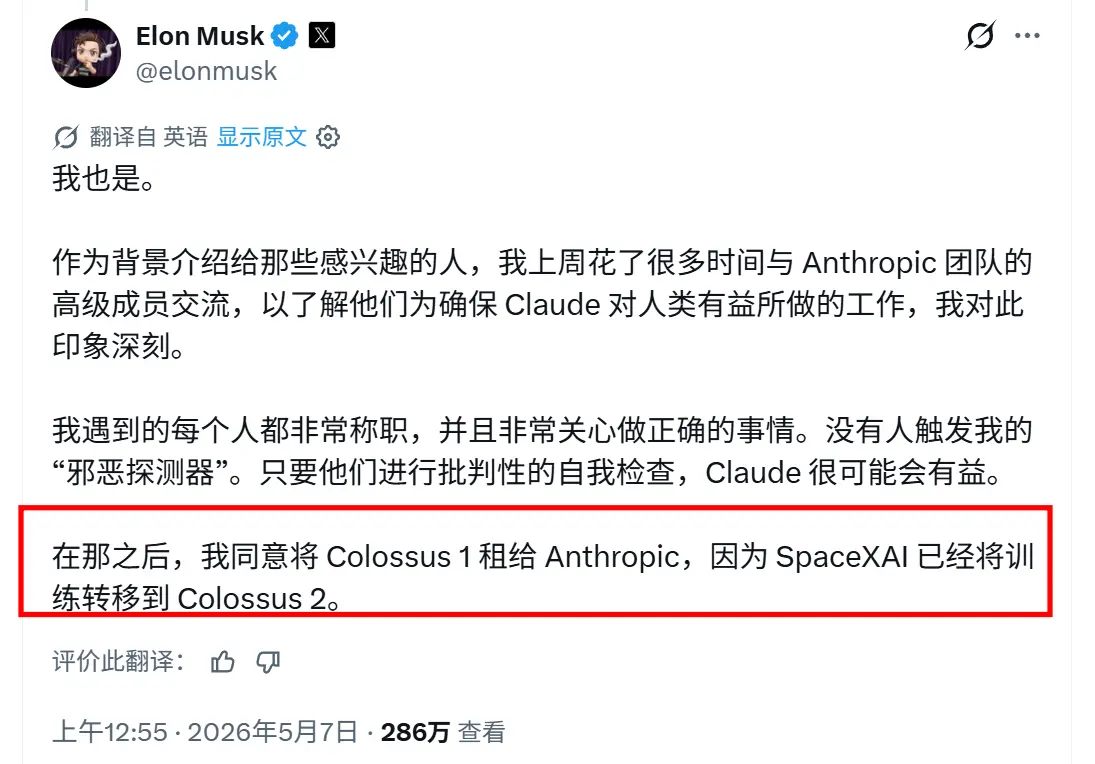
关键在后半句:
SpaceX/xAI 已经把训练迁到 Colossus 2 了。
这句话给了 Colossus 1 外租一个完整解释:
- Colossus 1 已经从 xAI 的最核心训练资源,变成可商业化的成熟产能;
- Colossus 2 承担 Grok 后续训练;
- Anthropic 拿到短期急需的算力,xAI 拿到现金流、合作关系和基础设施定价权。
Grok 被放弃了吗?#
事实上xai最近频繁更新了很多功能,比如Computer是今天才爆出的功能:
- Grok Computer:xAI 正在往 computer use 和 agentic workflow 方向扩展。
- Grok 4.3:xAI 文档把它作为多数文本、代码和推理工作负载的推荐替代模型;
- Connectors on Grok Web:Grok 网页版接入 Google Workspace、Notion、GitHub、Linear、SharePoint、Outlook、OneDrive 等工具;
- Grok Imagine Quality Mode API:图像生成质量模式进入 API,强化真实感、文字渲染和创意控制;
xAI 在模型下线说明里给出的迁移方向,是把旧模型迁到 grok-4.3、grok-4.20-non-reasoning 和 grok-imagine-image 等新模型,看上去只是一次常规的模型升级。旧模型下线会影响开发者体验,尤其是只有几天迁移窗口的生产系统;但从产品节奏看,这是一次非常激进的模型生命周期管理。
所以,Colossus 1 外租并不代表 Grok 业务停摆。从 xAI 最近的产品动作看,Grok 还在继续推进。更合理的观察点是:Grok 是否能在 Colossus 2 上训练出足够有竞争力的新模型。
Colossus 1 和 Colossus 2数据中心对比#
先说一下AI 算力对比的四层口径:
| 口径 | 适合回答什么问题 | 局限 |
|---|---|---|
| GPU / TPU / Trainium 芯片数量 | 直观看规模 | 不同芯片无法逐张等价 |
| H100 等效 | 粗略比较训练资源代际 | 换算依赖假设,误差很大 |
| EFLOPS | 比较理论峰值算力 | FP16、BF16、FP8、FP4 混算误差大 |
| GW / MW 电力容量 | 判断数据中心上限 | - |
对比一下 xAI 自己的两座核心数据中心。
| 维度 | Colossus 1 | Colossus 2 |
|---|---|---|
| 状态 | 运行中,租给 Anthropic | 已上线,仍在扩容 |
| 位置 | Memphis, Tennessee,原 Electrolux 工厂 | Memphis / Southaven 周边 |
| GPU / 加速器规模 | 22 万+ NVIDIA GPU;常见整理口径约 23 万 | 55 万级 Blackwell 部署;部分报道按 GB200/GB300 节点口径解释,物理 GPU 数可能更高 |
| 功率容量 | Anthropic 官方口径:300MW+;其他报道常见 250-300MW | 约 1GW 已上线,目标约 1.5GW;部分扩建口径提到 2GW |
| 芯片类型 | H100、H200、GB200 | GB200、GB300 为主 |
| 当前用途 | Anthropic 使用,提升 Claude 容量 | xAI / Grok 训练主力 |
Colossus 1 芯片包含22 万张以上 NVIDIA GPU,300MW+ 容量:
| 芯片 | 数量 |
|---|---|
| H100 | 约 15 万 |
| H200 | 约 5 万 |
| GB200 | 约 3 万 |
Colossus 2 已上线,属于 55 万级 Blackwell 部署,目标功率约 1.5GW。
这些数字到底有多大#
一个非常粗略的量级感:
| 对象 | 规模口径 | 备注 |
|---|---|---|
| Colossus 1 | 22 万+ NVIDIA GPU,300MW+ | Anthropic / xAI 官方确认 |
| Colossus 2 | 55 万级 Blackwell 部署,约 1-1.5GW | 已上线,仍在扩容 |
| Colossus 1 + 2 | 约 77 万级加速器部署口径,约 1.3-1.8GW | 取决于 Colossus 2 的节点 / GPU 解释 |
| Meta | 35 万 H100,近 60 万 H100 等效 | Meta 官方 2024 年底目标 |
| AWS Project Rainier | 近 50 万 Trainium2;Anthropic 已使用超过 100 万 Trainium2 | AWS / Anthropic 官方口径 |
| OpenAI Stargate | 美国 10GW 级基础设施承诺;部分海外项目单站 10 万 GPU | OpenAI 官方以 GW 和投资额披露,非 GPU 总数 |
| Google TPU | v5p 单 Pod 8960 芯片;更大 TPU 总量未公开 | Google 官方公开的是产品 / Pod 规模,缺少全网总量 |
美国前沿 AI 公司(xAI、OpenAI、Anthropic、Meta、Google)正在建设 10 万~50 万 GPU 级的单体训练集群,并向 GW(吉瓦)级供电的数据中心演进。xAI 的 Colossus 已达到约 20 万 GPU、300MW 级别,Meta 则公开表示拥有约 35 万 H100 和接近 60 万 H100 等效算力。
对比一下中国的 AI 算力总量,业内普遍认为,中国拥有数十万级 NVIDIA AI GPU 存量,并部署了大量国产 AI 芯片,但真正能够长期集中调度、用于超大规模训练的先进 GPU 集群规模,仍明显小于美国头部 AI 公司正在建设的 10 万~50 万 GPU 级 AI Factory。
当前中美差距的核心在于:
- 最新 AI 芯片获取能力(H100/H200/GB200 等)
- 单体训练集群规模
- 超高带宽互联与软件栈成熟度
- 一家模型公司长期独占调度的大规模训练资源
中国在“超大规模、连续、集中式 frontier 模型训练”这一层面,仍与美国头部 AI 公司存在差距。
结论#
模型榜单上的差距,往往只是最后显现出来的结果;更早发生的差距,藏在芯片采购、电力审批、机房建设、网络互联和工程调度里。一个国家或一家公司能不能做出下一代模型,越来越取决于它能不能把几十万张卡、GW 级电力和持续试错的工程系统组织起来。
算力不是智能本身,但它正在决定谁拥有反复试错的资格。没有足够大的训练集群,就没有足够密集的实验;没有足够密集的实验,就很难追上前沿模型的迭代速度。